Problem Statement:
The client organization currently relies on Python scripts and CSV files for data processing and analytics. To enhance real-time data updates, improve efficiency, and leverage cloud-based analytics, the organization aims to migrate existing Python-based workflows to Databricks using Spark SQL while integrating Sigma’s input table functionality. This transition will enable external users to provide real-time inputs, transforming the data dynamically and creating insightful visualizations in Sigma.
The core objective is to migrate existing Python workflows to Spark SQL in Databricks while replacing CSV file-based inputs with Sigma input tables. The migration should ensure data integrity, performance optimization, and real-time data updates in Databricks views, ultimately enabling better decision-making through Sigma dashboards.
Solution Overview:
Requirement Analysis and Stakeholder Engagement:
- Conduct detailed requirement analysis sessions with stakeholders to understand the current Python-based workflows.
- Document existing data dependencies, transformations, and performance benchmarks.
- Define success criteria and key performance indicators (KPIs) for the migration.
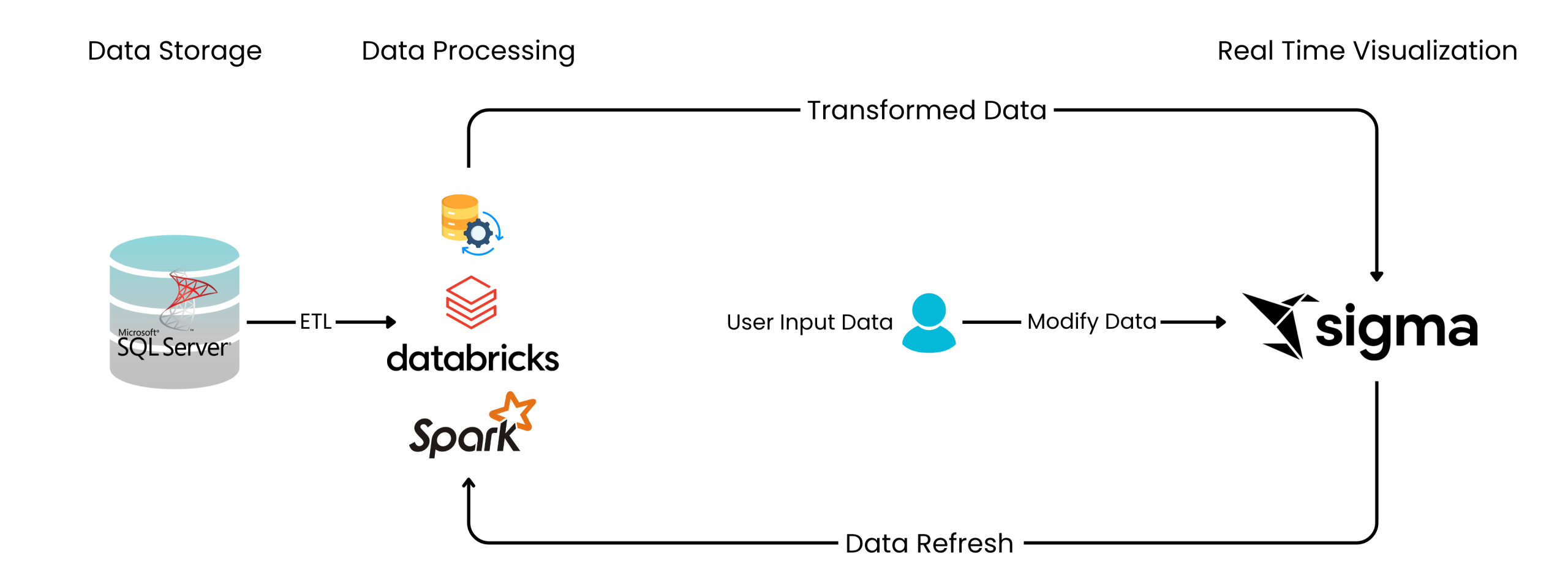
Integration of SSMS Database with Databricks:
- Establish a connection between the SQL Server Management Studio (SSMS) database and Databricks as a foreign catalog.
- Ensure smooth integration to allow direct querying and transformation of SSMS tables in Databricks.
Integration of Sigma with Databricks:
- Connect Sigma with Databricks to facilitate real-time data synchronization.
- Implement Sigma input tables, allowing external users to enter and modify data dynamically.
- Enable these input tables to update warehouse views in Databricks in real-time.
Data Transformation and View Creation Using Spark SQL:
- Utilize foreign catalog tables in Databricks to perform necessary transformations.
- Create transformed views in Databricks that aggregate and enrich the input data.
- Ensure that views update dynamically as users provide inputs in Sigma tables.
- The view updates dynamically as data changes in Sigma input tables.
- The foreign catalog tables from SSMS serve as the primary source for transformations.
Visualization in Sigma:
- Integrate Databricks-transformed views with Sigma.
- Create dashboards in Sigma using both Sigma warehouse views and Databricks-transformed views.
- Ensure real-time reflection of data changes in Sigma visualizations.
Code Migration and Optimization:
- Translate existing Python scripts to Spark SQL for efficient transformations in Databricks.
- Optimize transformations to fully utilize Databricks’ distributed processing capabilities.
- Replace CSV-based input handling with Sigma input tables to streamline data updates.
Integration and Testing:
- Integrate the newly developed Spark SQL-based transformations into the Databricks environment.
- Implement automated testing scripts to validate functionality and performance.
- Conduct performance tuning to ensure faster processing and real-time updates.
Deployment and Monitoring:
- Deploy the transformed workflows into the production Databricks environment.
- Set up monitoring tools within Databricks to track performance and detect issues.
- Implement automated alerts for data processing failures or performance degradation.
Documentation and Training:
- Document the entire migration process, including technical details of the new Spark SQL workflow.
- Provide training sessions and materials for end-users and support teams to familiarize them with the new system.
Tech Stack Leveraged:
- Azure Databricks (Spark SQL) for scalable data processing.
- Sigma Computing for real-time input tables and visualization.
- SQL Server Management Studio (SSMS) for data storage and querying.
- Azure Storage for data persistence and backup.
- Databricks Monitoring Tools for tracking system performance.
Benefits Delivered:
- Real-Time Data Updates: Users can input data in Sigma, and the changes reflect instantly in Databricks views and dashboards.
- Scalability & Performance: Migrating to Databricks with Spark SQL enables efficient distributed processing, reducing processing time significantly.
- Cost Reduction: Eliminates dependency on CSV file-based workflows, reducing data redundancy and manual handling.
- Advanced Analytics & AI: Leverages Databricks for machine learning and predictive analytics beyond traditional SQL transformations.
- Seamless Collaboration: The integration of Databricks and Sigma enables multiple teams to work collaboratively with real-time data insights.
- Improved Decision-Making: By replacing static CSV files with dynamic Sigma input tables, stakeholders can make data-driven decisions more effectively.
This migration ensures that the client organization transitions smoothly to a cloud-based, scalable data processing environment while enhancing real-time analytics capabilities.