

Problem Statement:
A leading SAAS provider in the home inspection industry, was facing significant challenges with platform stability and speed, particularly during high-traffic periods.
- The platform was unable to handle peak traffic, leading to regular downtime during critical periods.
- High latency during user interactions caused frustration and reduced customer satisfaction.
Impact:
These issues were negatively affecting user experience and overall customer sentiment, creating a substantial risk to the company’s reputation and growth.
To address these concerns, client engaged us to conduct a comprehensive assessment of their infrastructure and provide a solution to modernize their platform. The core objective is to migrate existing SAS workloads to Azure Databricks with minimal disruption while ensuring data integrity, performance optimization, and leveraging Databricks’ capabilities for advanced analytics and machine learning.
Assessment:
We began with an in-depth assessment of client’s existing infrastructure, focusing on key performance metrics, system architecture, and operational workflows. This evaluation involved several advanced tools and techniques to ensure a thorough analysis:
1. Performance Metrics Review:
- CloudWatch (AWS): Used to monitor and gather key system metrics such as CPU utilization, memory usage, and response times, providing a real-time view of the platform’s performance.
- New Relic: Deployed to analyze application performance, track error rates, and pinpoint specific areas where slowdowns occurred, especially during peak usage periods.
- JMeter: Conducted load testing to simulate peak traffic scenarios, helping to identify the system’s breaking points and areas of performance degradation.
- SonarQube: Utilized to assess code quality across the application, detecting potential issues such as code smells, bugs, and security vulnerabilities that could contribute to instability.
2. Infrastructure Evaluation:
- AWS Trusted Advisor: Used to evaluate the current server configurations, identifying instances that were either under-provisioned or over-provisioned, and recommending optimizations.
- AWS Well-Architected Tool: Assessed the architecture against best practices, focusing on operational excellence, security, reliability, performance efficiency, and cost optimization.
- Database Performance Analyzer (SolarWinds): Provided insights into the performance of the existing MySQL 5.7 database, identifying slow queries and other performance bottlenecks.
This comprehensive assessment, supported by these advanced tools, provided a clear picture of the underlying causes of the platform instability and performance issues, leading to the identification of several critical challenges that needed to be addressed.
Challenges:
1. Stability and Speed Issues:
These issues were primarily due to technical debt, outdated infrastructure, and the platform’s inability to handle higher-than-usual loads during busy seasons. The risk of a major outage was estimated at over 95%, necessitating urgent action.
2. Outdated Architecture:
The evaluation revealed that infrastructure was a mix of legacy systems, some over 20 years old, which were not equipped to handle the needs of a modern, high-demand application. The primary issues included:
- No Auto-Scaling: The platform lacked the ability to automatically scale resources during peak times, leading to frequent crashes.
- No Self-Healing: Servers did not have the capability to recover automatically from failures, requiring manual intervention that often resulted in extended downtimes.
- Legacy Database: The outdated database was identified as a significant performance bottleneck and posed security risks due to end-of-life vulnerabilities.
- Lack of Standardization: The absence of standardization across applications led to management challenges and increased the complexity of maintenance.
- Missing Indexes: Missing indexes were drastically slowing down query performance. It caused increased CPU and I/O usage, leading to longer load times and reduced system efficiency.
Solution:
1. Comprehensive Infrastructure Overhaul:
To address the above challenges, a strategic plan was implemented to modernize the platform’s infrastructure, focusing on stability, scalability, and speed:
- Server Capacity Upgrade: The initial step involved upgrading RDS capacity to handle the increased load, with additional upgrades planned as needed.
- Database Upgrade: Migrating from MySQL 5.7 to MySQL 8 to resolve vulnerabilities and improve query performance.
- Containerization: Transitioning the application to a containerized environment for better scalability and manageability.
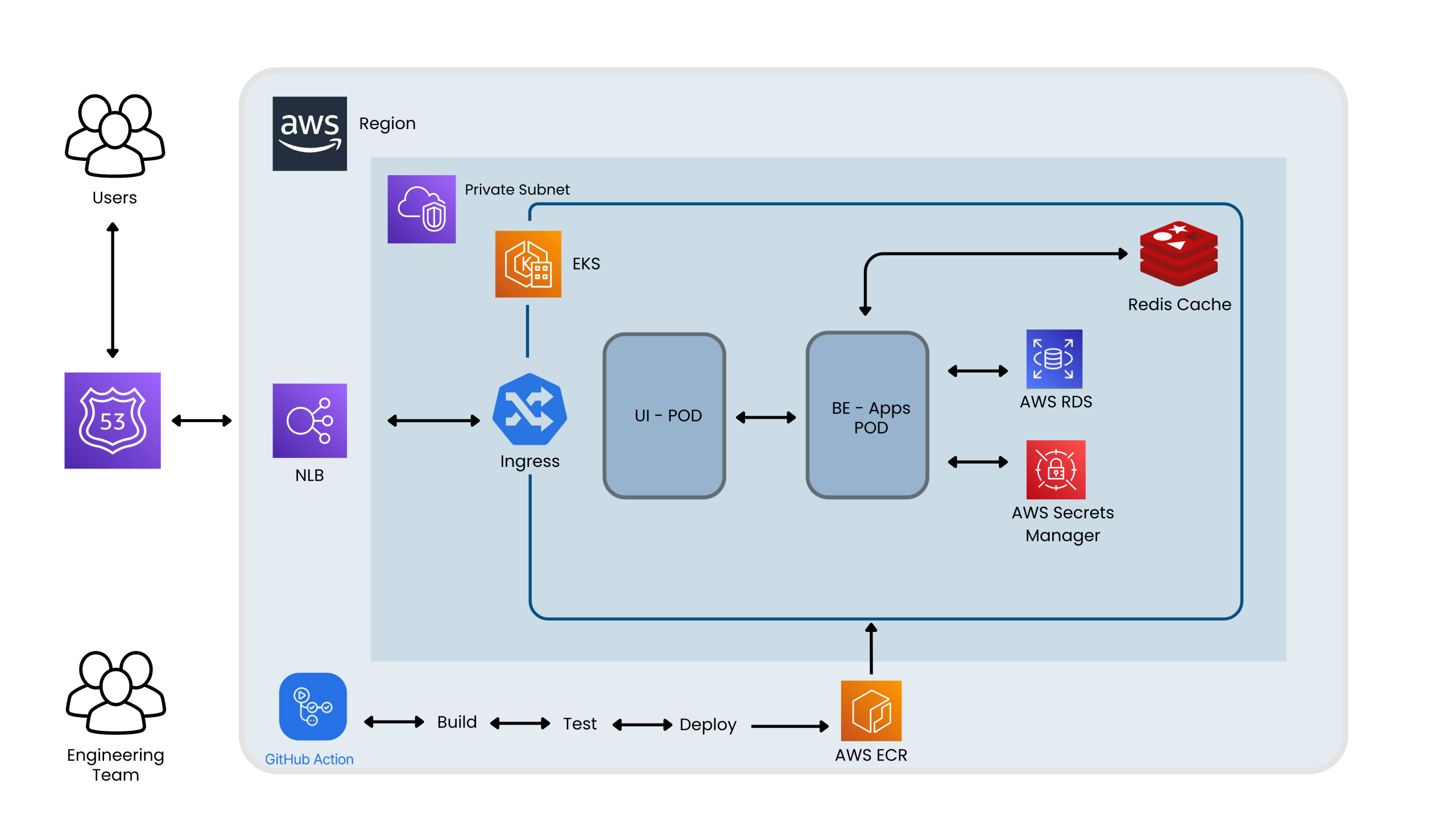
- EKS Implementation: Moving from EC2 instances to Amazon EKS for auto-scaling, auto-healing, and optimized infrastructure costs.
- Addition of missing indexes: Created the necessary indexes based on the analysis to optimize query execution. Focus on frequently used columns in WHERE clauses, JOIN conditions, and SELECT statements.
- User Requests Management: Utilizing Amazon Route 53 to manage user requests efficiently, with integration into a Network Load Balancer and Kubernetes Ingress controller for secure, consistent application exposure.
Streamlining Code Promotion: The development process was streamlined with GitHub Actions triggering code changes, creating new Docker images, and deploying them through Amazon EKS clusters for different environments (dev/staging/production). This ensured continuous delivery of stable, tested updates.
Key Benefits:
- Self-Healing: Amazon EKS now automatically detects and replaces unhealthy instances, minimizing downtime.
- Auto-Scaling: The platform dynamically scales to meet demand, preventing overloads and ensuring high performance during peak periods.
- Improved Database Performance: The upgraded database not only resolved security issues but also significantly improved query speed and efficiency.
- Standardization: Centralized deployment processes and containerization streamlined management and reduced the risk of errors.
- Stable Code Deployment: The introduction of unit testing and automated deployment processes ensured that only stable, tested code reached production, enhancing overall system reliability.
Results:
1. Enhanced Stability and Speed:
The infrastructure overhaul resulted in a marked improvement in platform stability and speed. Client successfully avoided further outages, even during peak traffic periods, and system performance was significantly enhanced.
2. Scalability and Resilience:
The shift to Amazon EKS and the implementation of auto-scaling and self-healing capabilities enabled platform to scale dynamically in response to demand. This not only improved user experience but also optimized infrastructure costs by scaling down during low-demand periods.
3. Improved Customer Sentiment:
With a stable and responsive platform, client saw a recovery in customer sentiment. Users experienced fewer interruptions, and the platform’s performance boost contributed to a better overall user experience.
4. Future-Ready Platform:
A modernized infrastructure is now equipped to handle future growth and evolving user needs, with the flexibility to adapt to new technologies and business requirements.

